
While at RTC 2013 as I looked around the exhibit hall I half-jokingly started saying “we’re going to be the 159th company with a content management solution!”. You start to question what makes you think you’re different. Why hasn’t this problem been solved? I think the answer probably lies in the fact that it’s hard to get people to change their habits and that’s what most solution providers have offered. In regards to change, I often say “of course it’s hard, it’s biological. We’re wired for stability, not change”. An exercise in futility would be to bank on convincing people that a new process will be better.
We started asking anyone that would indulge more questions about how they manage content and kept hearing a couple of things over and over. When asked how they manage their centralized libraries of content there was 100% unanimity. Heads would inevitably lower and voices soften as if embarrassed by their answer. The dark chorus was in unison on their reliance and contempt of Windows file folders. We had more than a hunch that would be the answer. After asking the first couple of dozen times and hearing the same answer from teams that ranged in size from a handful to thousands we knew there was an opportunity to try to help solve a big problem.
Windows file folders make for a terrible database. I think everyone can testify that digging through directory trees to try to find something can be a frustrating experience. When added up would you want to know how much time you waste each year digging? A couple of minutes here, ten minutes there, no occurrence is painful enough to cause a revolution but in aggregate the pain is real. It’s the classic “death by a million cuts”. With Windows file folders, each individual file is relegated to a single location or worse, copies have to be made if you want the same thing accessible in different locations. Why do we do this?
We also had a suspicion (I’m painfully aware of my own habits) that many people also “keep their own local stash” apart from the central repositories. When asked how much of that went on in their operations that reality was also confirmed. But perhaps more interestingly, we began hearing another theme. When you need something, particularly AEC-related content, you’re likely to try to dig back through an old project file to find it rather than fight the Windows folders someone spent an inordinate amount of time organizing. “Hey Bob, what was that project where we used x” or “Kim, do you remember if we used x in project y?”. And then off you go, a new scavenger hunt. Sound familiar? The archived project file served as a better database than the central file folders!
Parsing these hundreds of conversations led us to identify what we think is at the core of efficiently getting to the content. Context matters. Duh! It’s how people think. We’re frustrated with Windows file folders because it forces us to try to think in unnatural ways. We dig back into archived projects for nuggets of gold because the initial project context was a well-defined path and the first thing that entered our brain when those synapses started firing. If you enjoy learning about this kind of thing you should read Daniel Kahneman’s Thinking Fast and Slow. It helps explain not only how people think but why our brains are wired that way. Here’s the short version… the brain is an amazingly complex organ, biologically wired for efficiency. Given this understanding, we think the way we go about organizing and accessing content needs to change.
File Folders Do Serve A Purpose
The reality is that the Windows file folder can work… for the person who created them. That’s why everyone else (sans the person who created them) gets frustrated with central repositories. It’s also why everyone keeps their own stash. It fits “their” context, at least until it doesn’t. Those file folders can work as a logical way to store content. All those files have to be named something and physically go somewhere, don’t they! The trick is to separate the problems. Divide and conquer. Treat the storage problem separately from the retrieval problem. This led us down a new path.
AVAIL
With all of this newfound knowledge, we set out to attack the problem in a new way. #159 will be different! We established these primary criteria for a solution…
- Don’t disrupt current workflows. It’s futile to start there. Rather, augment what’s already going on.
- Don’t require anyone to move their existing content (ie. you can leave it in those awkward Windows file folders). Admittedly this was probably driven initially by a desire to position opposite all of the “store it in the cloud” offerings that are popping up daily, but in reality, it’s about separating the storage problem from the retrieval problem. Who cares where the content lives as long as your users can get to it easily. Moving content “to the cloud” doesn’t solve the context/retrieval problem.
- Provide the end-users with a visually driven, context-sensitive way of finding content.
- Be content agnostic. There is any number of important types of files that need to be centralized, organized and retrieved.
Here’s how AVAIL works. First, we let you create Channels for accessing content. The concept of a Channel in AVAIL is the primary way of beginning to provide the proper context for content. You can create any number of Channels and each Channel can contain any combination of content.
Secondly, want to build two or more Channels that contain some of the same content? You can, and without making copies of the file(s). AVAIL doesn’t move content around, it’s indexed. That’s how we begin separating where the content is “stored” from how it is “consumed”. The index provides flexibility on the front end. It lets you get to content from multiple entry points (Channels) and is the key to providing unlimited contextual entry points to the same piece of content.
Thirdly, provide a visual way to drill down to the content you need. AVAIL does this with a new tag-driven filtering technology we call Panoply. Panoply provides the ability to create contextually sensitive arrangements of tags per Channel. As you click on Tags in the Filters panel of a Channel you are essentially expressing intent, a direction. Tags that are irrelevant based on your choices disappear. It’s a dynamic contextual path of sorts. It’s one of those things you have to experience to fully appreciate its effectiveness. A massive amount of meta-data can be encoded as Tags and arranged for the logical context in AVAIL. You can parse through thousands of files to get to just the right content in a handful of clicks. Need to see the same content in a different context? The same content can live in a different Channel with filtering designed to fit the new context.
DW_AVAIL_Panoply
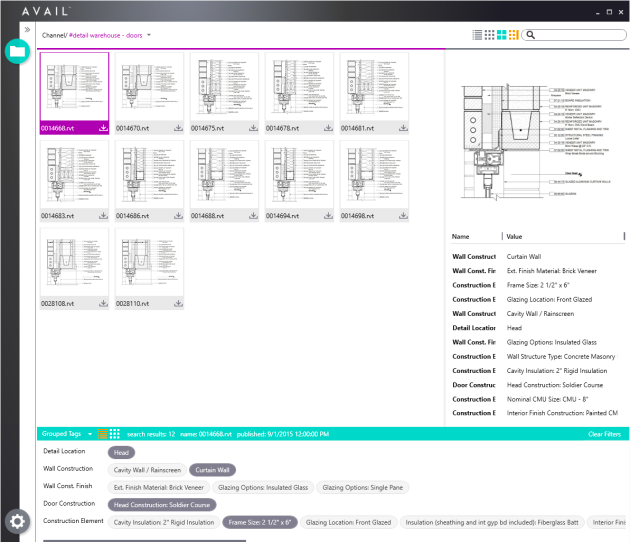
We think we’re onto something and working hard to fulfill the promise. The first place you can experience AVAIL and the new Panoply approach to filtering is in the recently released Detail Warehouse product. AVAIL is providing the interface for managing a library of over 27,500 native-built Revit Drafting Views. We’ll also be showing off AVAIL at a couple of events before the end of the year. Look for us at the RTC Europe (booth# 18) event in Budapest, Hungary at the end of October and soon after at Autodesk University (booth# 1213) the first week of December in Las Vegas, NV USA. If you can’t catch us at any of those events you can sign up for updates at avail.archvision.com.




