How is AVAIL using artificial intelligence (AI) and machine learning (ML) to make workflows easier for professionals in the AEC industry? Over the last year, we have been running a series of experiments leading us closer to an AI assistant that can help tag and suggest content for your Revit projects and more, as well as custom AI chatbots that can read your AVAIL channels and answer questions about your own data. Founder and CEO Randall Stevens shares his (early) thoughts on AI in AEC, the compelling experiments the team has been working on, and what we’ve learned so far. Our experiments may not be as “sexy” as text-to-image AI applications, but their potential to solve the AEC industry’s unstructured data problem cannot be ignored.
Quick Guide
- Making sense of the AEC industry’s mountains of unstructured data
- AVAIL’s compelling AI and ML experiments
- What’s next? Need for human-in-the-loop model training
- Key learning: “Garbage in, garbage out”
Making Sense of the AEC Industry’s Mountains of Unstructured Data
“It’s compelling,” are the words I’ve been using the last few months to describe the artificial intelligence (AI) and machine learning (ML) work that we’ve been pursuing at AVAIL. It’s compelling enough to keep pushing these initiatives forward.
Like most everyone in the industry—or world for that matter—we’ve been looking at, experimenting with, testing, and generally just trying to wrap our heads around where there are opportunities to leverage the recent advances in AI and ML.
Underlying many of the problems in the AEC industry is the presence of mountains of relatively unstructured data. We’ve been working for years toward bringing more structure to our customer’s content environments with AVAIL. The more context you can add to content, the more promising new ways of getting to that information become.
"Underlying many of the problems in the AEC industry is the presence of mountains of relatively unstructured data."
Most of the attention the past couple of years in the AEC industry was given to generative AI in the form of text-to-image applications like Midjourney, DALL-E, and Stable Diffusion. It’s sexy and understandable why designers and creatives in the industry flocked to those early incarnations of generative AI.
In no way do I want to diminish the importance of the text-to-image advancements, but there are many, not-as-sexy, applications of AI in the AEC world that need to be explored.
It’s in these more mundane areas where we’ve been spending our time. After discussing this recently with someone in the industry, they made the comment that this was “doing God’s work.” There’s plenty of work to be done.
We've spun up a series of research experiments over the past year, venturing into the world of AI and ML. Our goal with these experiments is to make it easier and easier for practitioners and content managers to move through their firms’ mountains of data.
We want to help you auto-tag like content. We want to auto-generate relevant content from similar past projects into new projects. We want to give your team the power to train an AI chatbot with your own data, so the information it shares is relevant and reliable.
Managing information in the age of AI will require a platform specifically designed for the incredible volumes of content AEC teams are sorting through on a regular basis. With our AI and ML projects, the team at AVAIL is making its content management system ever more useful for BIM managers, designers, technology directors, and more.
Our first experiment began in quarter-three of last year. Over the course of not even a full calendar year, we have significantly increased the sophistication of our efforts and gathered a good amount of compelling results, too. We can’t wait to see where we’ll be in just a few short months.
AVAIL’s Compelling AI + ML Experiments
Before we get into the details, it is important to first answer the question, “Why?” AI and ML will change the way we think about “search” and how people interact with information. The results of our experiments so far are leading us in two major directions:
(1) AVAIL Suggestion Engine
This will become the preferred AI assistant for increasing design and engineering efficiency. Our auto-tagging efforts for both Revit Details and content greatly improves search and identification, as well as the ability to associate content automatically.
(2) Custom Chatbots fed by AVAIL Channels
From onboarding and training new hires to helping firms respond to RFPs based on historical responses, custom chatbots fed by a customer’s AVAIL Channels are some of the most compelling work we’re doing. We can imagine chatbots for efficient retrieval of building product manufacturer information, interaction with “Lessons Learned” databases, and so much more.
"AI and ML will change the way we think about “search” and how people interact with information."
We think the work outlined below will become the underpinnings in helping to solve the challenges of our mountains of content.
If you have a mountain you’d like to make searchable and easier to navigate, please reach out!
| Experiment # | Project | Start Date | Status |
| 1 | Auto-tagging Revit Details | Q3 2023 | Success! |
| 2 | Auto-identifying project building types | Q4 2023 | Success! |
| 3 | Auto-identifying Revit Families | Q1 2024 | Early stages, but very promising results |
| 4 | AVAIL Help Center Chatbot | Q1 2024 | Success! Currently being refined by Success Team |
| 5 | Custom chatbots for AVAIL Channels | Q1 2024 | Early stages, but results are compelling |
Experiment 1: Auto-tagging Revit Details
Problem:
Our first work started last summer as we began looking at the possibility of auto-identifying the components of details. We had volumes of training data available from our sister company ArchVision that manages and distributes its Family + Detail Warehouse product with AVAIL. The collection houses over 27,000 native Revit Details (you read that right!) along with approximately 1,000 native Detail Items that were used in their construction.
Given that volume of content to chew on, we were interested in seeing if we could use the Detail Items to train an AI model, which could then find those items in Revit Details.
rESULTS:
We were able to successfully train a model to identify the general type of Detail (roof, foundation, etc.) and had promising results in beginning to train a model on the more difficult task of identifying individual Detail Items within a single Detail.
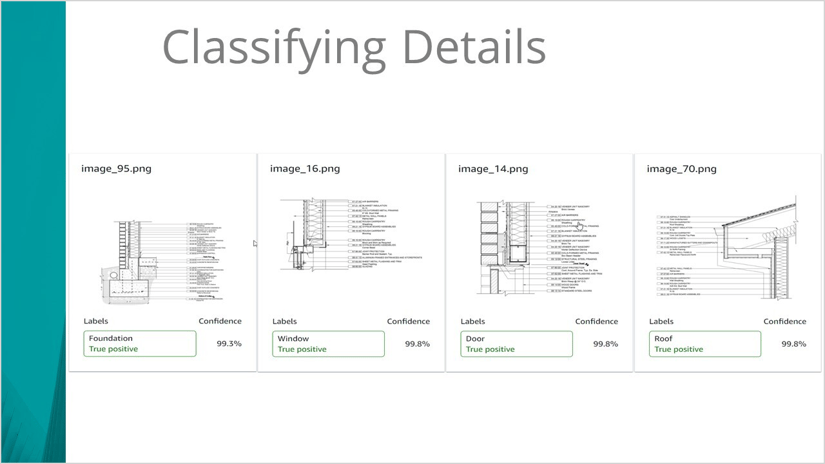
Classifying details with a high degree of accuracy!

The tougher challenge of identifying detail items within a detail!
Use Cases:
We presented these results at last fall’s Confluence event which focused on advancements in AI + ML in AEC. This was the start of our exploration and immediately we saw the potential in helping to solve challenges such as:
- Auto-tagging details for quick search and identification
- Recognizing when a detail has changed from a standard and identifying what has changed
Experiment 2: Auto-identifying Project Building Types
Problem:
We began by identifying 150 types of buildings. Is it an apartment building, a museum, a parking garage, or an airport terminal?
We wanted to build a system that could accurately identify a project building type knowing only the project name. Some names are easy if they contain the building type in the project name but others aren’t so evident.
rESULTS:
We’re now successfully identifying with ~95% accuracy the building type provided only the project name!
uSE cASES:
- Being able to identify the building type while looking at historical project data allows us to more accurately identify important information needed in future projects
- Knowing the building type at the start of a project allows us to bring relevant content for use in that project
Experiment 3: Auto-identifying Revit Families
Problem:
On to the next challenge, which is a little more complicated. Given the success of identifying building types from project name(s), we set our sights on being able to identify technical content using only their filename. We know most people continue to use “encoded language” to stuff as much identifiable information into the names of their files.
rESULTS:
We’re in the early stages of this project but seeing very promising results. Further refinement is going to require help in fine-tuning the model. We plan to implement this through human-in-the-loop interface(s) within AVAIL that can be used to provide the expertise needed to accurately fine-tune to our customer’s own data.
We opted to start this project leveraging the OmniClass classification framework which describes nearly 7,000 product components and assemblies used in building construction.
We have a great collection of Building Product Manufacturer mechanical, electrical, and plumbing (MEP) content in the AVAIL Select MEP and Architecture channels, with over 5,000 native Revit Families from over 50 industry-leading manufacturers to lean on in this process.
We focused on the HVAC category. Using the Revit 2024 Out-of-the-Box content, we’re getting the following results:

uSE cASES:
- Auto-tagging content for improved search and identification
- Ability to associate content automatically
- AVAIL “Suggestion Engine” that will become the preferred AI assistant for increasing design and engineering efficiency
Experiment 4: AVAIL Helpdesk Chatbot
Problem:
Can we leverage the latest Retrieval-Augmented Generation (RAG) capabilities to “talk” with information in AVAIL?
rESULTS:
Yes! We started with a simple AI Chatbot that is focused on information housed in our AVAIL Help Center. This information focuses on learning how features work in AVAIL as well as common troubleshooting items. Most of that information is being housed in a HubSpot database used to drive the Help Center. There are also multiple training videos, housed on YouTube, where we were able to extract transcripts for populating the RAG.
We then developed a simple web-based AI chatbot interface that is now implemented directly in the AVAIL Desktop interface through our plug-in “Lens” architecture. As you can see from the results below, the future of the Help Center is going to change forever. Of special note is the ability to reference the source documents where the information was gleaned from. We believe this will be an important aspect of delivering confidence in the results that are returned during these early stages of implementation.
Use Case:
We plan to implement the AVAIL AI chatbot soon with a goal of letting our customers augment the underlying source(s) with their own information where appropriate. More on that below.
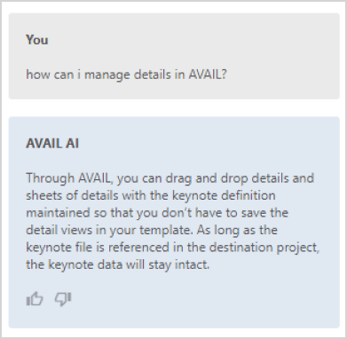
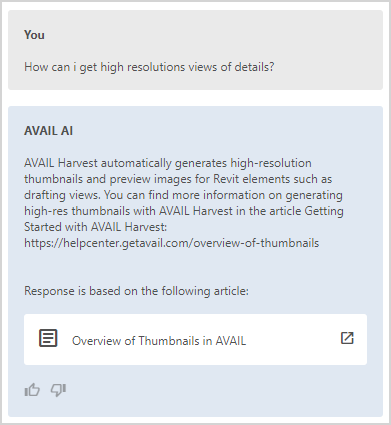
Experiment 5: Custom Chatbots for AVAIL Channels
Our second AI chatbot experiment has revolved around chewing on information being managed within AVAIL (not an external database), the goal of then being able to “have a conversation” with that content. Sounds cool, doesn’t it?
We created a channel in AVAIL and indexed PDF documents related to products in the AVAIL Select MEP building product manufacturer channel. Those PDFs are a subset of thousands being used to seed our new Related Content initiative.
rESULTS:
It’s not perfect (yet) but it’s definitely “compelling!” As you can see from the results below, the ability to interact in more natural ways with information is just around the corner. Our goal is to provide a means for AVAIL customers to manage their own information within AVAIL and then control access to their own chatbots that leverage that information and more importantly only that information in the responses.
We have several customers experimenting with using AVAIL to “chat” with their own information. If you’d like to learn more contact me.
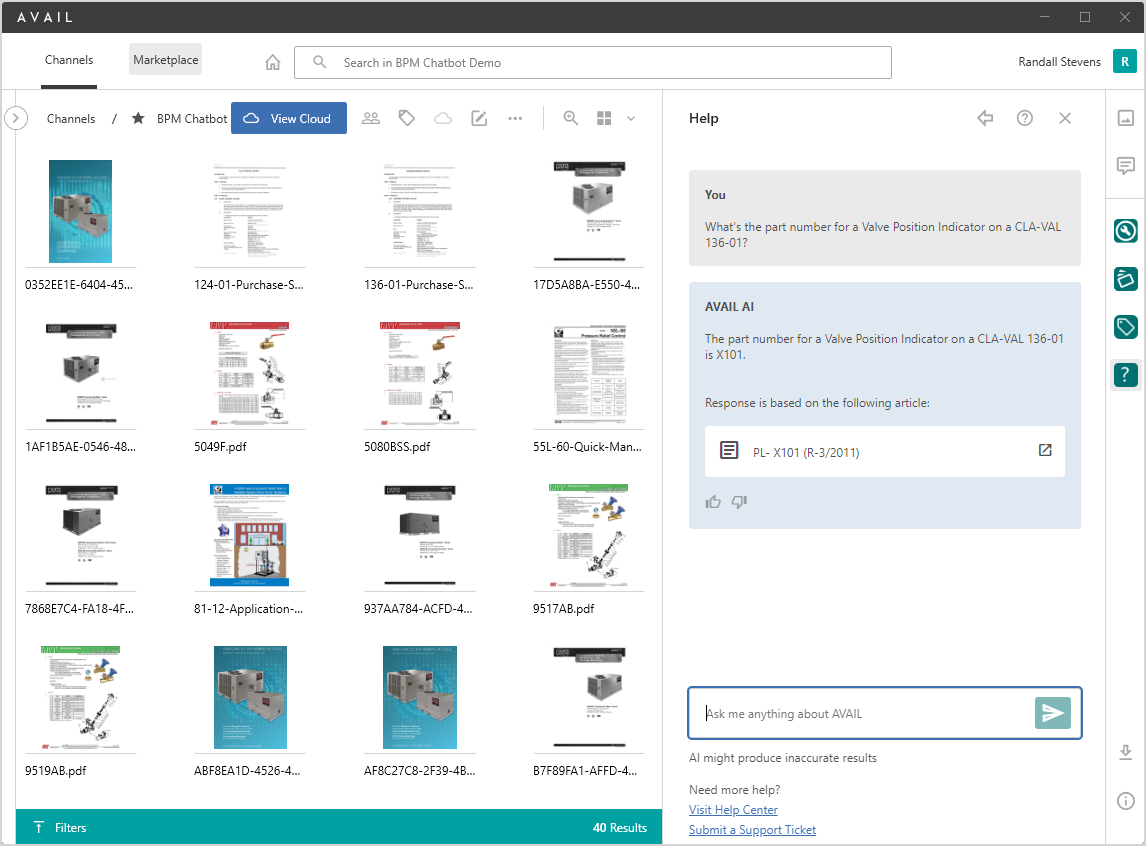

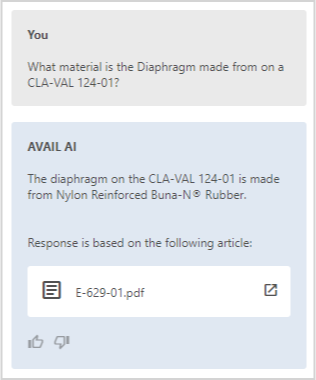
uSE cASES:
- Chatbot that can help with onboarding and training
- Chatbot for helping respond to RFPs based on historical responses by project type
- Chatbot for efficient retrieval of Building Product Manufacturer information
- Chatbot for interaction with “Lessons Learned” databases
What’s Next? Need for Human-in-the-Loop Model Training
As compelling as our early results with these technologies are, it is clear that there’s a need for informed human interaction with the underlying data to get accurate results. That’s a fancy way of saying you need people who know what they’re talking about correcting the errors exposed in the training data.
The work I outlined above showing the “hallucinations” around OmniClass identification are a prime example. How should those examples be classified? Nothing against youth, but I think this is a clear area where “seasoned” (I have to be careful as I've crossed the mid-50 threshold myself) professionals can drive the speed and quality of results from these new capabilities.
We’re planning to build a feedback loop into AVAIL for allowing those professionals to help train the models using their own data.
Key Learning: “Garbage In, Garbage Out”
You know the old saying, “If you’re a hammer, everything looks like a nail?” I might be guilty of this. As we’ve dug into these AI and ML experiments, it’s becoming more and more evident to me that underlying the utility of any of these new capabilities is going to be a need for better and better information management.
We call it content management, but it’s ultimately all a form of the same thing. As the volume of information increases you need better and better contextual, structured data around that information to make good use of it.
"Bad information yields bad answers.”
“Garbage in, garbage out,” is how the other saying goes. It means, if you want better output, the input must be constrained. If you feed your AI chatbot all of the information in the world, you will get hallucinations. Bad information yields bad answers. But, if you feed your chatbot good, reliable information from within your firm, you’ll get good information.
Content management is so important in the evolution of AI because the best information generally comes from the “edges” of a company.
"The best information generally comes from the edges of a company”
It’s the people doing the work that possess the most valuable information and understand its utility. They’re the ones who have to feed the bots. They’re the ones who have to train the assistants. They’re the only ones who know if the output is garbage or not.
That means they have to be in control: in control of the inputs and of validating the outputs.
Content management will ultimately underpin the success of most any successful AI implementation. While the backend infrastructure will be managed by your IT and technical teams, the information used to train the bots–which will have to be identified, vetted, pruned and… maintained—will come from within the organization at the business level. You’ll have to periodically add new and cull outdated information. This requires a content management layer to be sustainable.
My thesis when we started AVAIL was that every company building commercial software ends up spending 50-percent of its time (re)building content management tools. That’s a travesty. We’ve developed AVAIL to be agnostic and extensible to help reduce that waste in the AEC industry. AVAIL is poised to help accelerate the utility of your AI initiatives. I’m excited to share what we’ve been working on.
Want to know how others are experimenting with AI and ML in the AEC Industry?
If you happen to be in the New York City area on April 17, 2024, you should join the Confluence NYC event we’re hosting at the Brooklyn Navy Yard. It will be a day of talking about all things AI with conversations being led by thought leaders from Woods Bagot, Perkins&Will, Chaos, SHoP and Thornton Tomasetti.
About the author
 A software entrepreneur, Randall Stevens is passionate about creating solutions for the architecture, engineering, and construction (AEC) industry. He graduated in 1991 with a Bachelor of Architecture and shortly after founded the Rich Photorealistic Content (RPC)-focused company ArchVision. Leveraging his industry expertise further in 2016, Randall started content management system (CMS) AVAIL that now boasts Gensler, Perkins&Will, IMEG, LEO A DALY, and Populous as customers, among others.
A software entrepreneur, Randall Stevens is passionate about creating solutions for the architecture, engineering, and construction (AEC) industry. He graduated in 1991 with a Bachelor of Architecture and shortly after founded the Rich Photorealistic Content (RPC)-focused company ArchVision. Leveraging his industry expertise further in 2016, Randall started content management system (CMS) AVAIL that now boasts Gensler, Perkins&Will, IMEG, LEO A DALY, and Populous as customers, among others.




